
This post contains a guide on how to add columns to tables in SQL Server, with tips and links to Microsoft Documentation along the way.
As a SQL Server DBA, adding new columns to tables is a routine and simple task, often driven by evolving business requirements or application enhancements. However, when working with larger tables, replication and/or default values, special care is required to manage (potential) performance impacts and maintain system stability.
🗎 Read this before starting (Microsoft Docs)
1. How to Add Columns to a Table
2. Considerations for Schema Changes
3. How to Replicate Schema Changes
1. How to Add a New Column to a Table
To add a column to a table in SQL Server, use the ALTER TABLE statement. Here’s a simple example of adding a VARCHAR column that allows NULL values:
-- Add column to table mssql ALTER TABLE sqlBlog ADD tag VARCHAR(60);
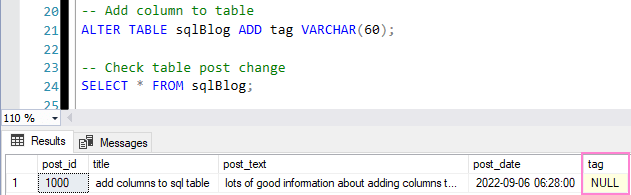
After execution, confirm the new column by querying the sys.columns system table. If we use this rather than running a SELECT Top 1 on the table we can avoid querying sensitive data.
2. Adding Columns to Tables with Default Values
Adding a column with a default value requires additional planning. SQL Server applies the default to all existing rows, which can trigger updates that affect performance and replication latency.
Here’s an example of adding a column with a default INT value:
-- Add column to table with default value -- CONSTRAINT = Optional constraint name ALTER TABLE sqlBlog ADD epmv INT CONSTRAINT epmv_def DEFAULT 12345 WITH VALUES;
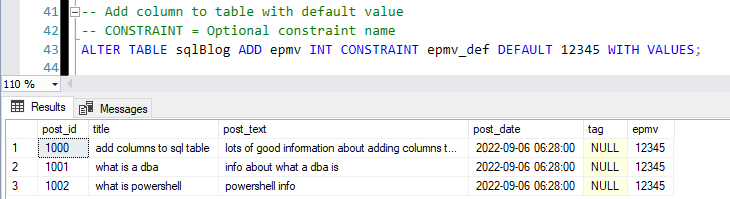
Explanation:
– CONSTRAINT: Specifies an optional name (epmv_def) for the default constraint.
– WITH VALUES: Applies the default value (12345) to all existing rows immediately after adding the column.
3. Tips for Dealing with Business Critical Tables
Consider the following when adding columns to tables that are critical to application functionality:
1. Check for Exclusive Locks
Changes to tables that are frequently being locked can cause the add column update to take a long time, or never complete. We can check for exclusive locks for a database in SQL Server using the script provided in my other blog post.
2. Managing Large Tables & Default Values
Adding columns with default values to large tables can lead to prolonged updates and transaction log growth. We can update values separately and not include it in the add column statement.
3. Monitor Replication Latency
In replication setups, schema changes automatically propagate to subscribers. Monitor latency closely using Replication Monitor or a custom script to keep track of delays at the distributor and subscribers.
4. Schedule Maintenance Windows
Communicate downtime and perform the operation during off-peak hours to minimize user impact.