
As a DBA, I’ve found Stack Exchange Data Explorer (SEDE) to be an invaluable tool for analyzing data from the Stack Exchange network. It’s essentially a web-based SQL playground, allowing you to run queries and uncover hidden insights without downloading any data. Just open the tool, write a query, and explore the results.
Why I Like SEDE
No setup required – It’s entirely web-based.
Pre-built queries – Use existing queries on topics like user activity, Q&A stats, and tag trends.
Easy sharing – Share your queries and visualizations with the Stack Exchange community.
The interface is smooth and intuitive. Each Stack Exchange site has its own database, and you can browse queries others have created or write your own.
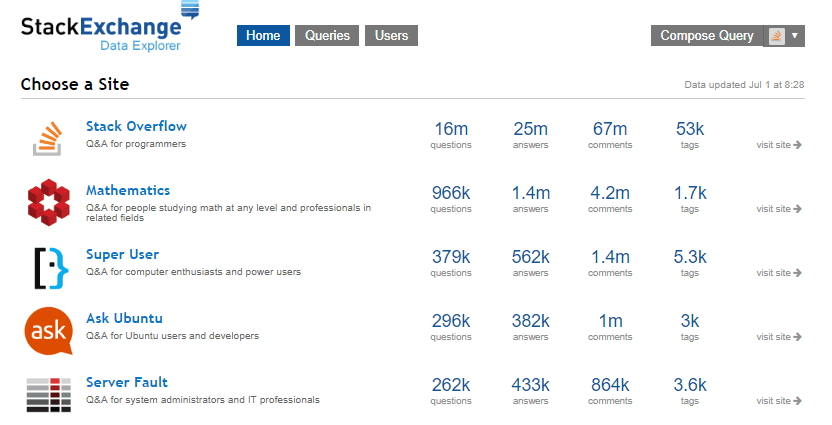
The interesting content is way down at number 24 (Database Administrator site) 😉

A neat feature I discovered by accident: running a query creates a fork, allowing you to modify and build upon existing work.
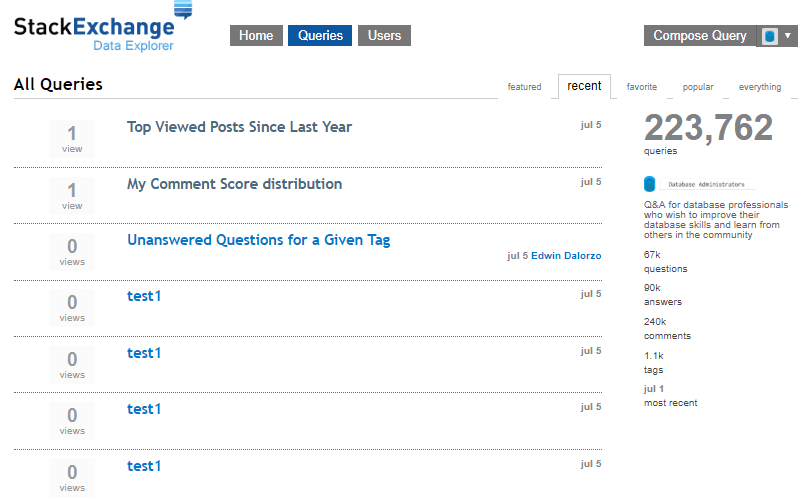
The top query above is my one. Here’s my example query that finds the top 10 most-viewed posts from the past year:
-- stack exchange data explorer, show top posts since last year SELECT TOP 10 Title, ViewCount, Score, Tags, CommentCount FROM Posts WHERE CreationDate > DATEADD(year, -1, GETDATE()) ORDER BY ViewCount DESC
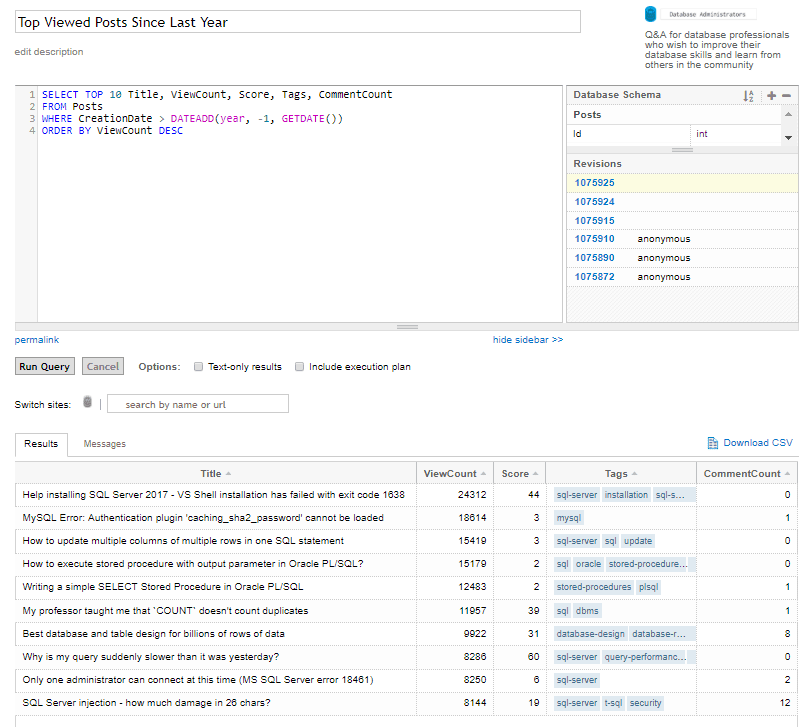
This is a great way to see trending topics and refine your SQL skills.
If you’re a DBA, data analyst, or just someone who enjoys working with data, SEDE is worth checking out. It’s a fun, powerful tool that makes exploring Stack Exchange data easy and engaging. I hope this was useful for you and you have already navigated away to check it out!
Leave a Reply