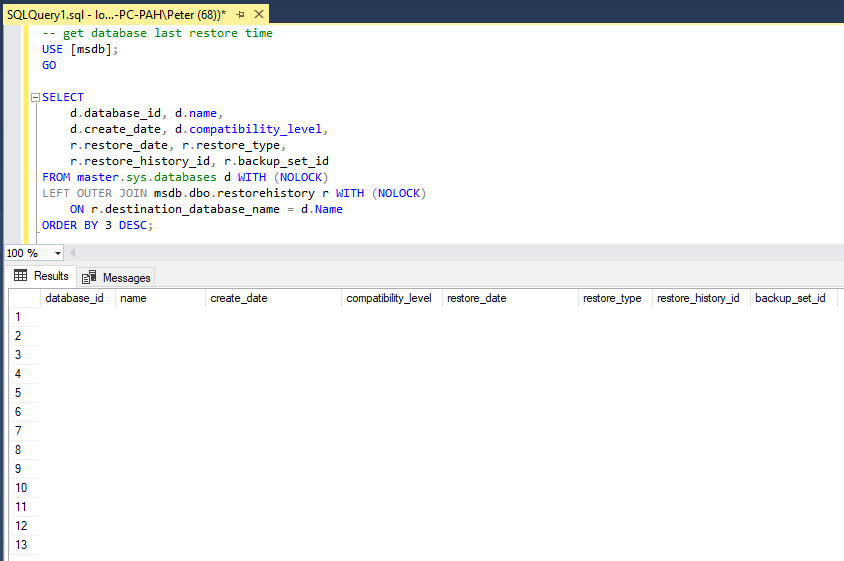
This post contains a script to help you get the last dates and times for when your databases were last restored in SQL Server.
The script below queries the M.S.D.B database sys.databases and restorehistory tables. You should get into the habit of searching MS Docs for every system table you query in SQL Server. This gives you the reference point you need for documentation on columns and query examples.
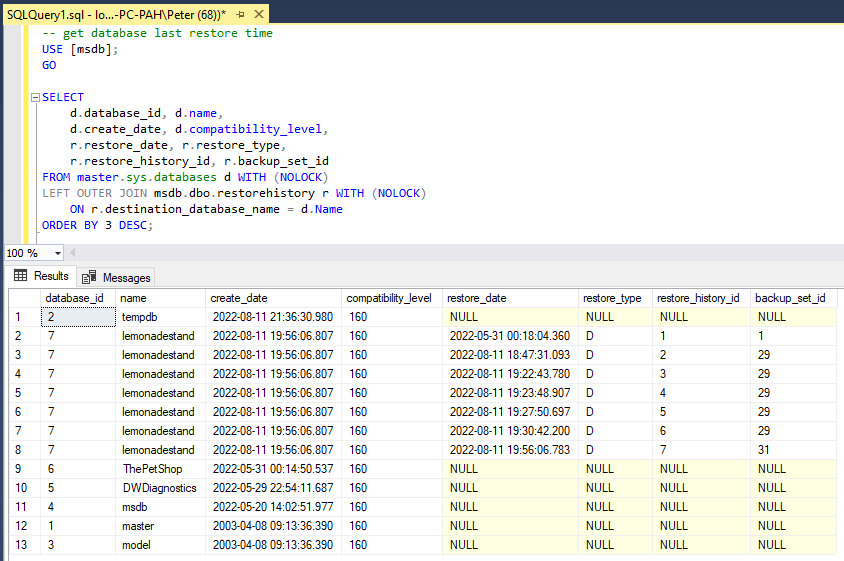
If your database was not created by a RESTORE procedure then the restore_date column value will be NULL. For example, if you’ve installed SQL Server and created a new database, then this script may not be of much use.
The above restore_type column shows ‘D’ to indicate a Full backup restore has happened. ‘L’ would indicate a transaction log restore, and ‘I’ is a differential restore. The column meanings can be found in the MS table docs as linked above in this post.
If you’re interested in reading more about querying SQL Server currently running processes, have a look at my MSSQL SPIDs blog tag, or have a look at my MS SQL DBA Blog Posts for random tips from a DBA.
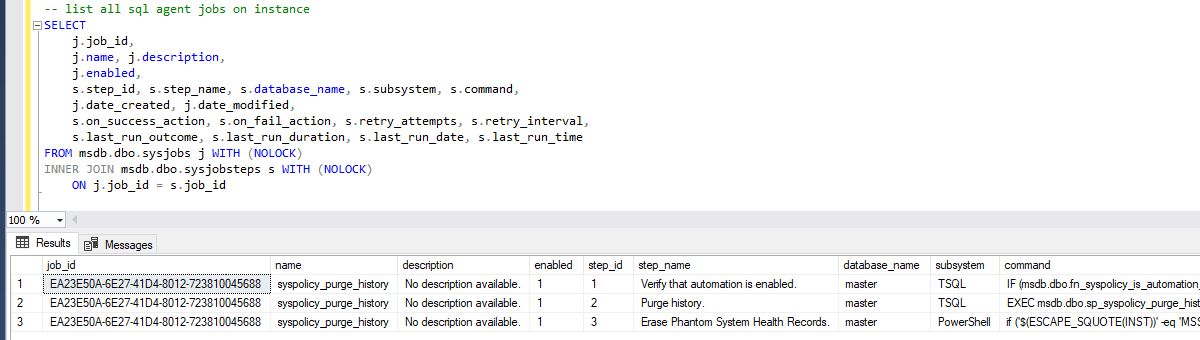
This post contains a SQL script that will return a list of all SQL Server Agent Jobs on a Microsoft SQL Server instance.
The sysjobs and sysjobsteps tables we are querying are in the M-S-D-B database. Interesting fact, I am unable to publish a post with this actual database name without seeing a JSON error.
When querying system tables in MS SQL Server, we should refer to Microsoft Docs as linked ^ MS Docs gives us a reference point for column definitions and the docs often include various example SQL code snippets.
List all SQL Agent jobs in SQL Server
As mentioned above we’re querying the M S D B database. The following script will return a list of all the SQL Agent jobs on the SQL Server host –
script to get sql agent jobs
This SQL script returns a row for each job step contained within an Agent job, including information such as whether the job is enabled/disabled, and the TSQL command text for the job step.
If you want to return only Agent Jobs, not including Job Steps, you can query the sysjobs system table on its own (SELECT * dbo.sysjobs). Whenever you are querying SQL Server System Tables and you need more info, MS Docs is always the place to turn to, as linked above in this post.
Restoring a database in SQL Server is a straightforward task, and one that SQL Database Administrators have to perform thousands of times throughout their career.
A database restore can be done via GUI (SSMS Wizard) or via command (TSQL/PowerShell). The method you choose to restore a database is usually driven by the number of databases you have to restore. If you have to restore more than 5 databases, perhaps it’s time to automate. If you are an experienced engineer you might write the restore command as second nature, always having it as a preference rather than restoring via the SSMS GUI Wizard.
One complexity when restoring databases is that your database backup media might be split into more than one file – this just means we need to add more paths during the restore.
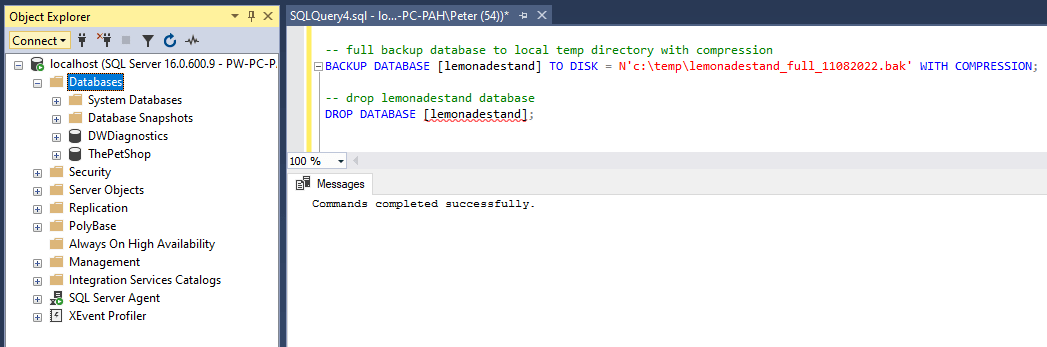
In the demo below I am running a Full Backup of a database, dropping it, and restoring it back online. Following this, I do the same again but split the backup media into more than one file.
I have 2 user databases on my local MSSQL instance here : [ThePetShop] & [lemonadestand]
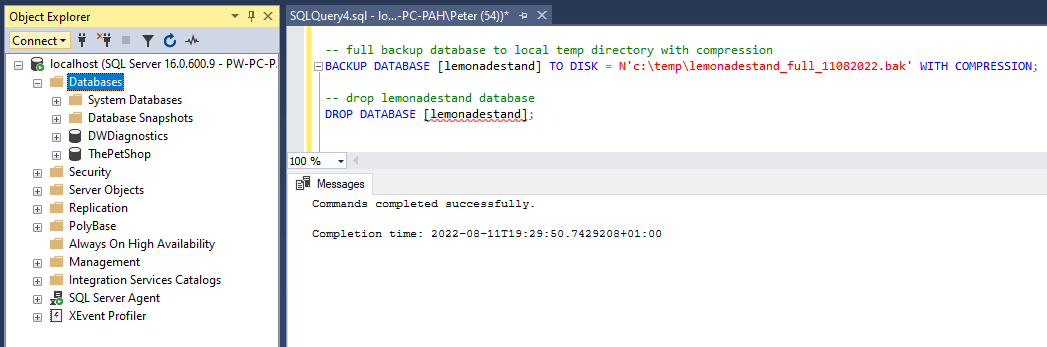
To prep for this database restore demo, I’m going to run a Full Backup for the [lemonadestand] database to a local directory.
-- Perform full database backup to local temp directory with compression
BACKUP DATABASE [lemonadestand] TO DISK = N'c:\temp\lemonadestand_full_11082022.bak' WITH COMPRESSION;
Next, I’ll drop the database and refresh my SSMS Object Explorer.
We no longer have the [lemonadestand] database available to us.
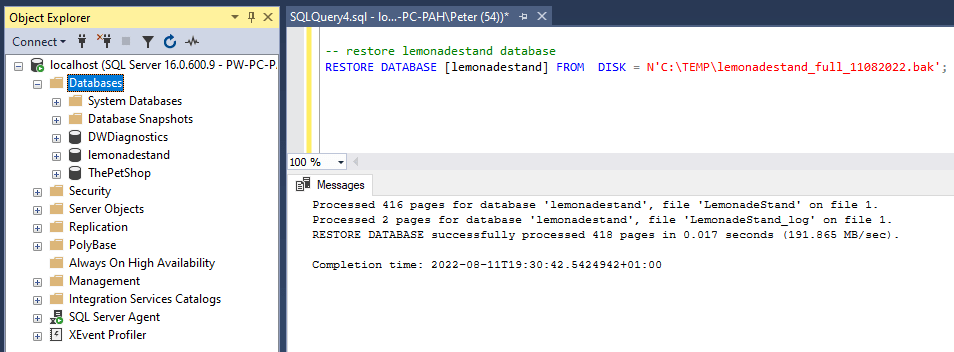
To restore this database, back to the point in time I ran the backup command, we need to run the RESTORE DATABASE command. I run the command and refresh SSMS.
-- Restore database ms sql
RESTORE DATABASE [lemonadestand] FROM DISK = N'C:\TEMP\lemonadestand_full_11082022.bak';
The database is now back online and ready to use again.
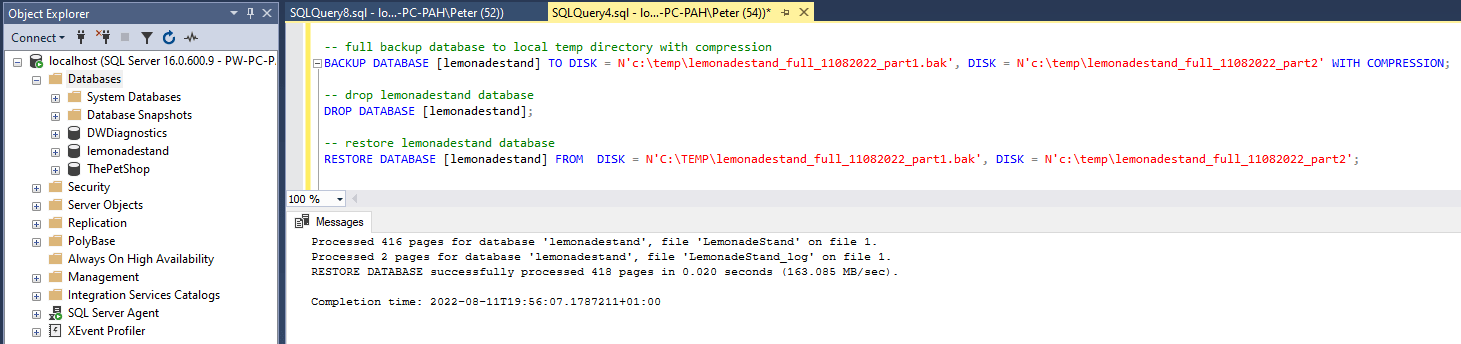
This time we are going to perform another Full Backup of the [lemonadestand] database, but this time splitting the backup media across 2 files instead of 1.
Backing up to multiple files is often used to improve performance for backups, and/or for managing available disk space on an MSSQL host.
-- Run Full database backup to local temp directory with compression
BACKUP DATABASE [lemonadestand] TO DISK = N'c:\temp\lemonadestand_full_11082022_part1.bak', DISK = N'c:\temp\lemonadestand_full_11082022_part2' WITH COMPRESSION;
-- Drop the lemonadestand database
DROP DATABASE [lemonadestand];
-- Restore the lemonadestand database
RESTORE DATABASE [lemonadestand] FROM DISK = N'C:\TEMP\lemonadestand_full_11082022_part1.bak', DISK = N'c:\temp\lemonadestand_full_11082022_part2';
That’s it for this one. Have a look at the Restoring Databases Tag for more tips on this area – I hope to touch on points in time recovery more.
Some time ago I wrote a blog post on why use WHERE 1=1 in SQL. This time it’s why use WHERE 1=2, but really this can be WHERE 1=9 or anything that isn’t a 1, we just want the false statement.
WHERE 1=1 is TRUE; has no difference on execution times and can be used for ease of adding/removing comments & commas on queries that you are building.
WHERE 1=2 is FLASE; is usually used for building the structure of a table by copying it from another, without copying any of the rows. It does not copy keys & constraints.
The following example SQL should help explain this, and the SQL Syntax used below can be run on any of the SQL Systems tagged in this post (MySQL, MS SQL, Redshift, Postgres & more).
The syntax will work on other SQL systems, however, the table names used in the SQL below will not be available on all platforms. Please amend SQL table names as necessary.
-- Create table copy from another table
CREATE TABLE infoschema_tables AS (SELECT * FROM REMOVEinformation_schema.tables WHERE 1=1);
-- Count rows of created table
-- (not required in this psql terminal example as it shows row counts)
SELECT COUNT(*) FROM infoschema_tables;
-- Drop table
DROP TABLE infoschema_tables;
-- Create table copy from another table but do not copy rows
CREATE TABLE infoschema_tables AS (SELECT * FROM REMOVEinformation_schema.tables WHERE 1=2);
-- Count rows of created table
SELECT COUNT(*) FROM infoschema_tables;
-- Clean-up drop table
DROP TABLE infoschema_tables;
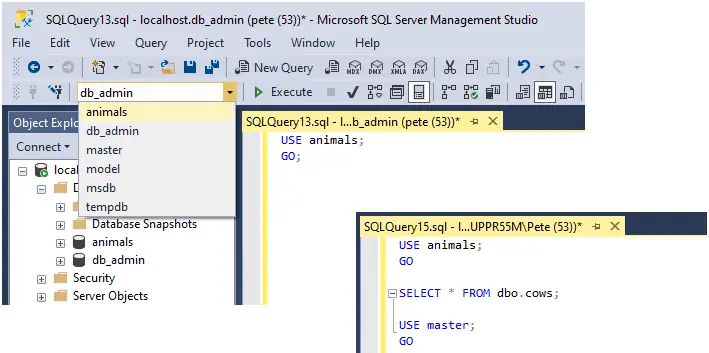
USE [database] in SQL Server is a way to change the context to a specific database when you are running a query in Microsoft SQL Server.
When you log into SQL Server using SQL Server Management Studio (SSMS), your database context will be automatically set to your default database which was set during the creation of your SQL login.
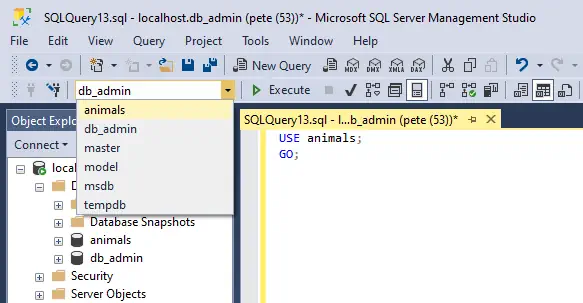
This means if you create a new query (SSMS Shortkey: Ctrl + N) in SSMS you’ll automatically be scoped to that database. You can switch context by selecting the drop-down menu in SSMS or by running the USE command:
-- Use database example sql server
USE [animals];
GO;
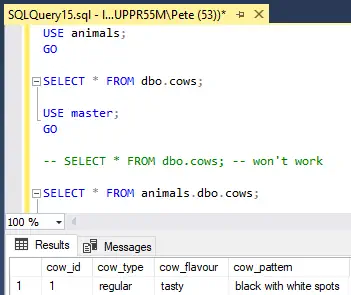
The USE command does not work with Azure SQL Database.
If you don’t know database names and can’t see them in the Management Studio (SSMS) Object Explorer, try to see if you can query sys.databases (SELECT * FROM sys.databases) to see if anything shows up.
This here is an example of the SQL USE command within a sequence of queries:
Another phrase that is used instead of ‘context switching’ is ‘scoping’. For example, this query is database scoped – meaning you should run the query within the context of a specific database.
A common SQL question is, why would anyone use WHERE 1=1 in their queries? And what does it do?
The WHERE 1=1 condition means WHERE TRUE. It returns the same query result as it would without the WHERE Clause. There is no impact on query execution time.
This is something you can add to a SQL query for convenience for adding & replacing conditions on the statement. If you have WHERE 1=1 on a SQL query you are writing, all conditions thereafter will contain AND, so it’s easier when commenting out conditions on exploratory SQL queries.
Example: WHERE 1 Equals 1
/* where 1=1 example */
SELECT *
FROM TABLE
WHERE 1=1
-- and column1='blah'
and column2='more_blah'
-- and column3 is not null
You can see this would be easier for commenting out WHERE conditions in the SQL ^
Example (Extra): Commenting Columns
This is similar to another SQL querying technique where you have commas before column names, rather than after the column name.
Again, this might work out well for you when commenting out columns on a work-in-progress SQL query.
SELECT
Column1
-- ,Column2
,Column3
,Column4
-- ,Column5
FROM TABLE
Personally, I often make use of both of the above techniques when I write SQL queries.
Convenience is everything when working behind a computer. We have to keep exploring new short keys and any general ways of working to optimize our efficiency. Some things you might not like and won’t adopt, and sometimes GUI is better than CLI. It’s all personal preference, in the end, choose what you are most optimal with.
If you wonder what would happen if we change the WHERE 1=1 to WHERE 1=2, have a look at my other blog post – Why Use WHERE 1=2 in SQL
As of the 2017 Edition of SQL Server we have been able to install SQL Server on Linux. Linux will likely be more of an unfamiliar environment for traditional Microsoft SQL DBAs. This guide should hopefully help you when you need to check the status of SQL Services and Stop/Start services on a Linux host.
The examples provided in this post utilise the systemctl command. Many Linux distributions use systemctl as a tool for managing services including CentOS, Ubuntu, Debian & RedHat.
Note that the systemctl command is not available in some Linux distributions, including if you are running Linux on WSL (Windows Subsystem for Linux). This is because Ubuntu WSL does not use the systemd init system, which is what systemctl is designed to manage.
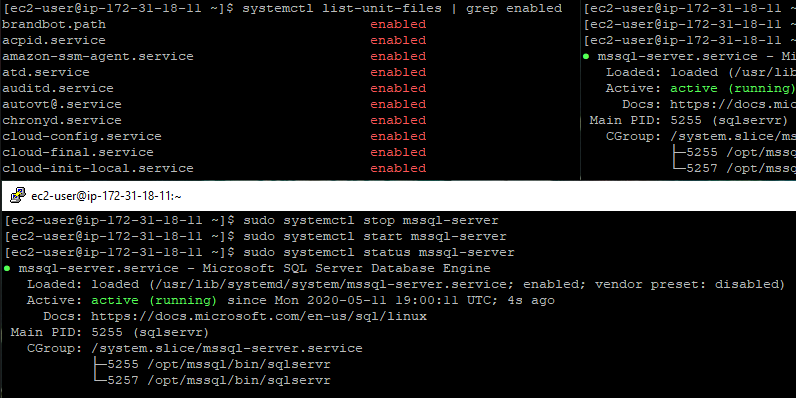
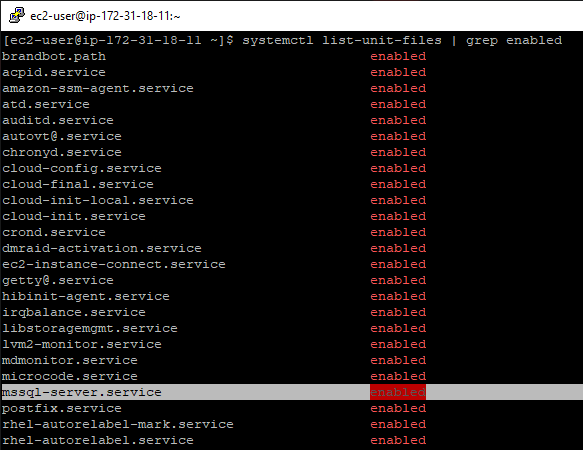
To show all enabled services on a Linux system, use the following command:
systemctl list-unit-files | grep enabled
If your service is not on the list of enabled services, it will not start automatically on the next system reboot. To enable the SQL Server service with systemctl, use the following command : sudo systemctl enable mssql-server
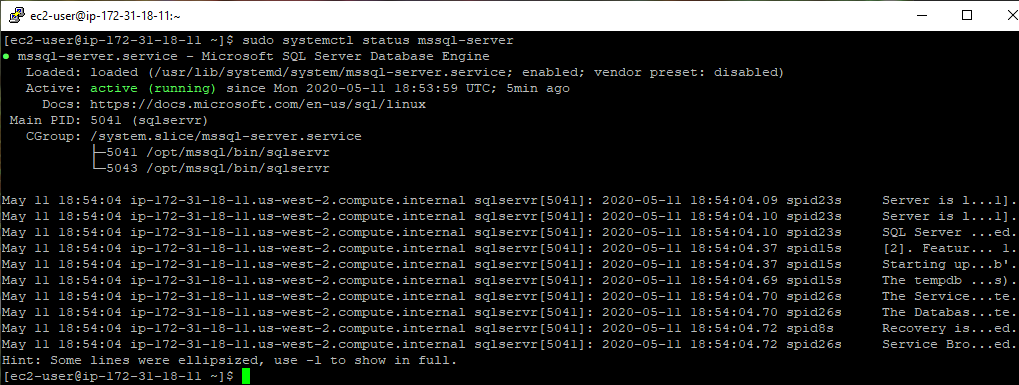
Check Status of SQL Server Service on Linux
The systemctl status mssql-server command is used to check the current status of the SQL Server service on your system. This command will display information about the service, including whether its currently active or not.
sudo systemctl status mssql-server
If the SQL Service is active, the output of the command will include the text “active (running)” in green. This indicates that the service is currently running and is available to process requests.
If the service is not active, the output will include the text “inactive (dead)” in red. This indicates that the service is not currently running, and may need to be started or restarted in order to be used.
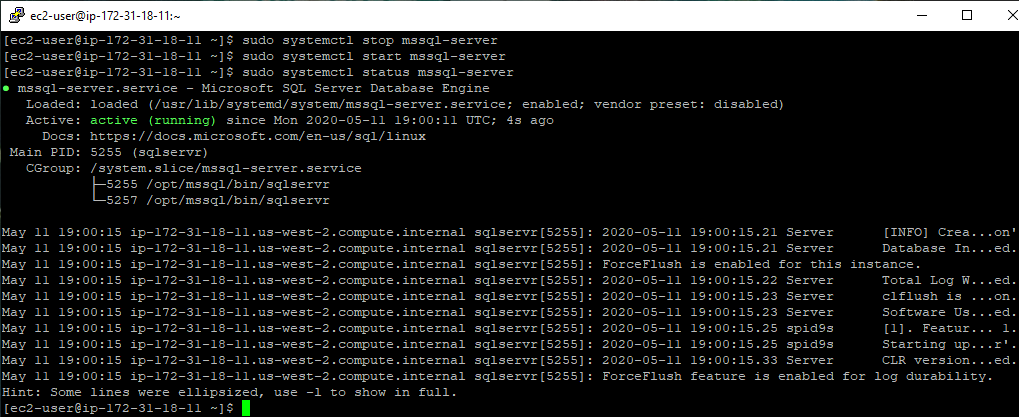
To stop, start, or restart the SQL Server service on Linux, you can use the systemctl command.
sudo systemctl stop mssql-server
To start the service again, use the following command:
sudo systemctl start mssql-server
To restart the service, use the following command:
sudo systemctl restart mssql-server
After running any of these commands, it is always a good idea to check the status of the service to make sure that the desired action was completed successfully. You can do this using the systemctl status mssql-server command as shown in the screenshot.
This is a post on how-to on changing the schema of a table in SQL Server, moving it from one schema to another using the ALTER SCHEMA [tableName] TRANSFER SQL statement.
During my time as a SQL Database Administrator, assisting with a task like this is a rare event. If you are more of a Database Developer, then you’ll probably need to do this more often.
If you are making this change to a Production SQL Server, you should ensure all SQL queries that use tables included in this change are updated with the new schema name.
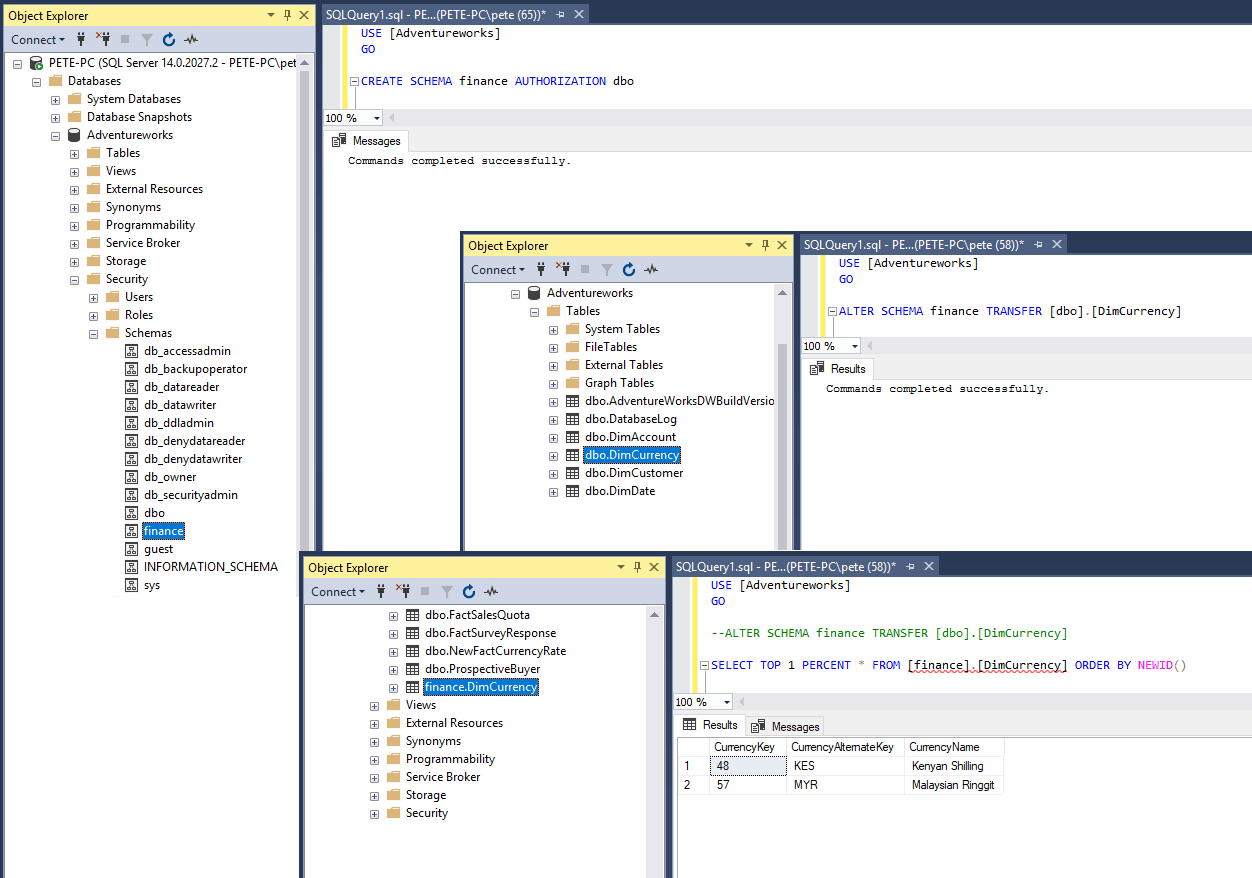
The SQL below will create a new schema within the [Adventureworks] database which will be the new schema we are migrating the test table to.
-- Create a new schema in MS SQL Server
CREATE SCHEMA [finance] AUTHORIZATION dbo;
Setting dbo as the owner will be fine in most cases. If you have experienced SQL Database Developers around you, they might ask for this schema to be created with an alternative schema owner.
We have our new schema created, now let’s move on to the next part for migrating a table to this schema.
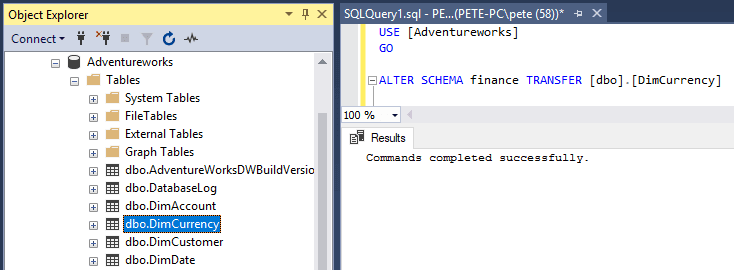
-- Change schema of table in SQL Server
ALTER SCHEMA finance TRANSFER [dbo].[DimCurrency]
The schema name in the left-most part of the SQL command is the schema we are transferring to (finance).
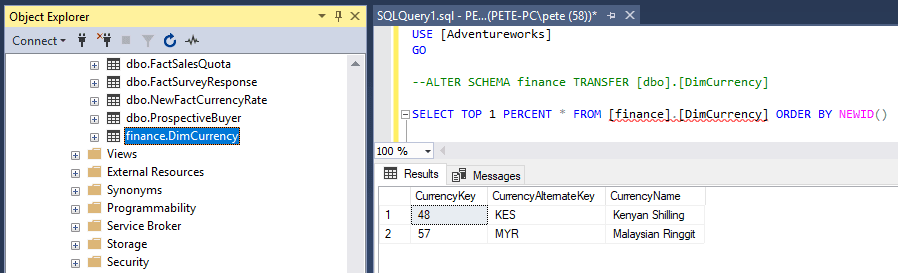
Now that I’ve created the new Schema, I’ll refresh the tables within the SSMS Object Explorer. I see the table has changed from dbo.DimCurrency to finance.DimCurrency.
(Note: the red squigglies under the table name in the SSMS query window mean that the query hasn’t been refreshed yet. Hit CTRL + SHIFT + R to update SSMS IntelliSense)
Remember to now update all queries, and change the schema name when querying the transferred table.
I hope this guide has helped you amend the schema of a table in SQL today. If you like this post and want more random tips from an MS SQL DBA, check out my latest posts on my DBA Blog Homepage.
There are many ways to check the size of a table in SQL Server. The way you will do it will likely depend on what your task at hand is.
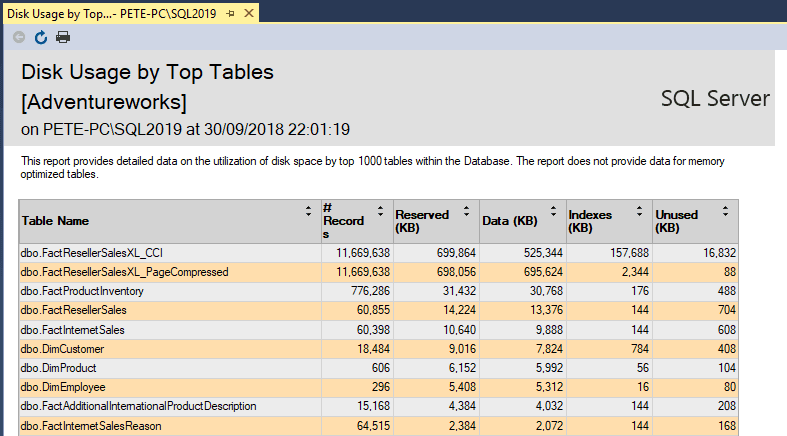
For example, a quick look at the Disk Usage by Top Tables report on a database you’ve never seen before would instantly show you the large tables in a database. But if you want this information saved somewhere else, e.g. to a table in SQL, it’s an easy task for us to run a TSQL script and output to Excel or CSV.
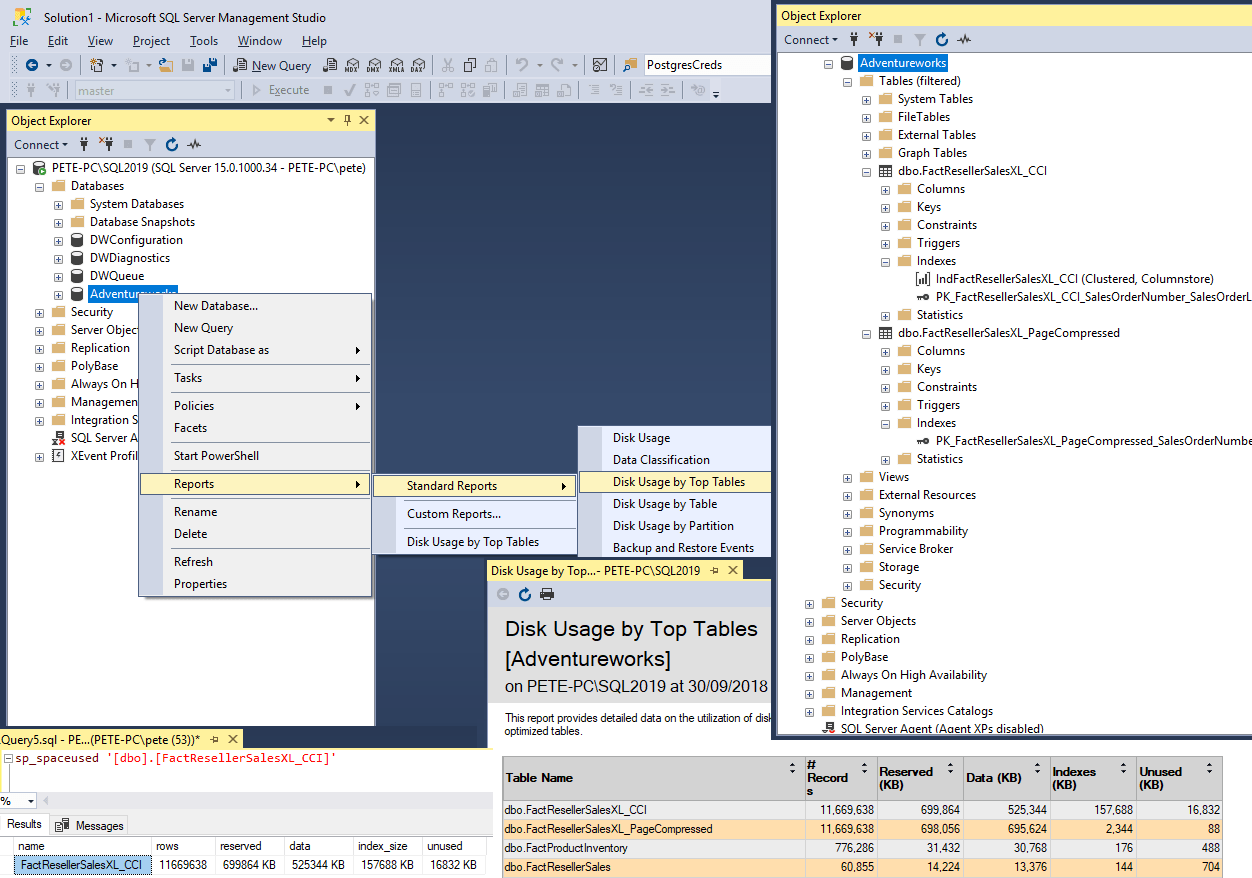
To open this report:- 1. Open SQL Server Management Studio (SSMS). 2. Expand Databases. 3. Right-click the Database and select Reports > Standard Reports > Disk Usage by Top Tables
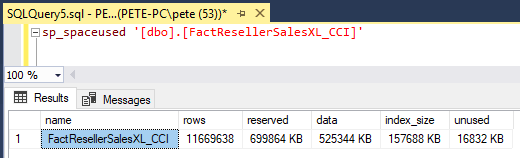
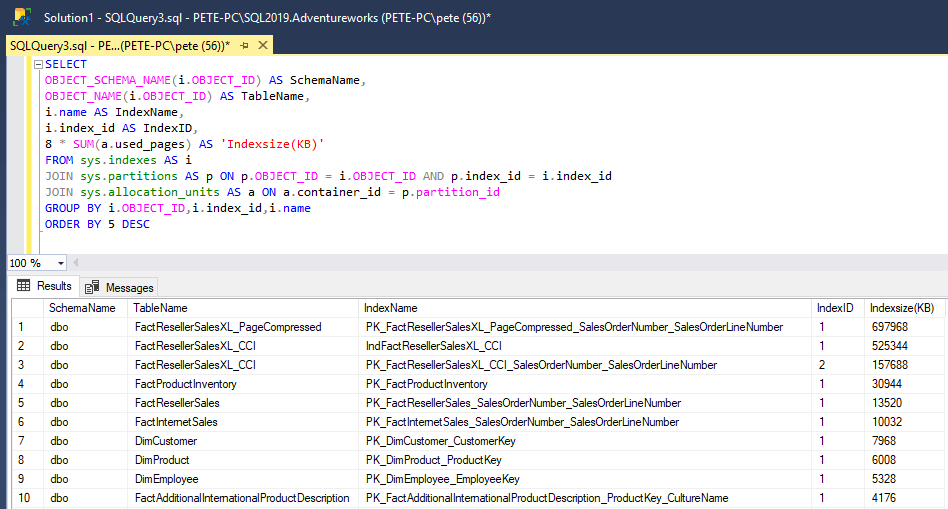
The report shows that this database has 2 tables close to 700MB in size, both containing the same number of rows but there are some differences in the indexes.
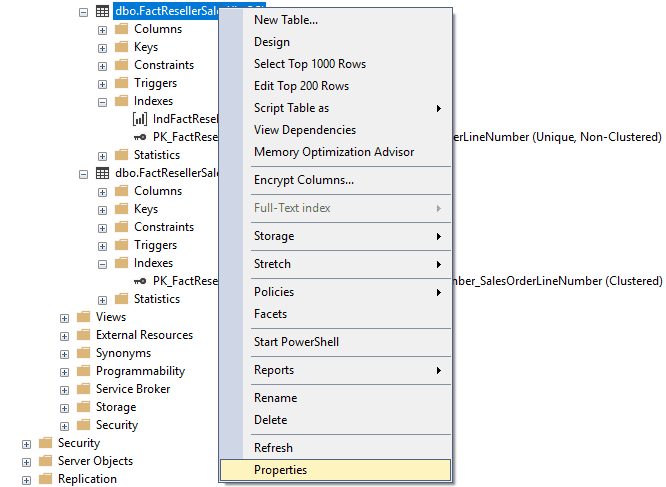
Another way to check the sizes of tables in SQL Server Management Studio (SSMS) is to open the Table Properties within the Object Explorer.
To do this, expand the database and tables. You may need to add a filter to find your table.
Now, right-click the table and select Properties as shown in the screenshot below.
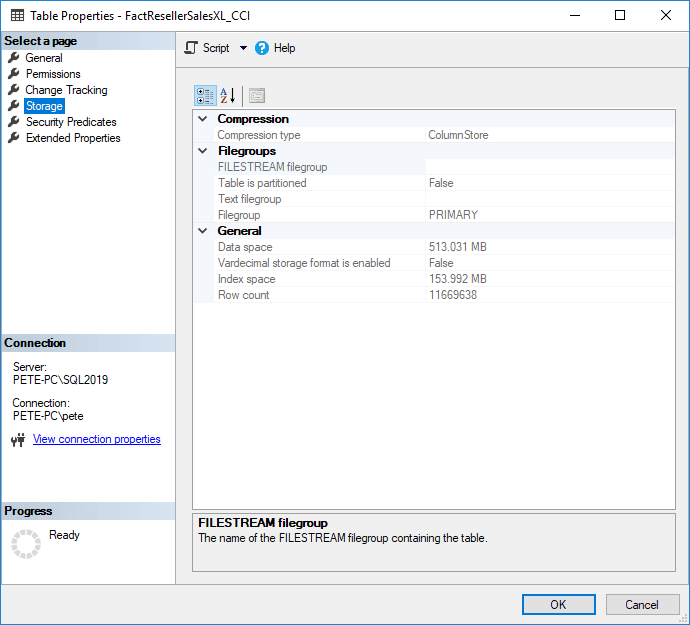
Open the Storage tab on the left-hand sidebar. It may take a second for the window to load, but this will show the index space, data space usage and the table row count.
Lastly, we can run a query on SQL Server system tables to get the table sizes.
-- Get Table Size SQL Server Script
SELECT
t.NAME AS TableName,
s.Name AS SchemaName,
p.rows AS RowCounts,
CAST(ROUND(((SUM(a.total_pages) * 8) / 1024.00), 2) AS NUMERIC(36, 2)) AS TotalSpaceMB,
CAST(ROUND(((SUM(a.used_pages) * 8) / 1024.00), 2) AS NUMERIC(36, 2)) AS UsedSpaceMB,
CAST(ROUND(((SUM(a.total_pages) - SUM(a.used_pages)) * 8) / 1024.00, 2) AS NUMERIC(36, 2)) AS UnusedSpaceMB
FROM
sys.tables t
INNER JOIN
sys.indexes i ON t.OBJECT_ID = i.object_id
INNER JOIN
sys.partitions p ON i.object_id = p.OBJECT_ID AND i.index_id = p.index_id
INNER JOIN
sys.allocation_units a ON p.partition_id = a.container_id
LEFT OUTER JOIN
sys.schemas s ON t.schema_id = s.schema_id
WHERE
t.NAME NOT LIKE 'dt%'
AND t.is_ms_shipped = 0
AND i.OBJECT_ID > 255
GROUP BY
t.Name, s.Name, p.Rows
ORDER BY
t.Name
That’s us done for now. For more SQL Tips from a random MS SQL DBA in the field, feel free to check out my SQL DBA Blog page which includes a list of my latest posts.